
In a previous post, I talked about TCO (Tail Call Optimization) and was not sure how Rust handled it. Some one on reddit responded and noted that Rust does not do anything with this, but the LLVM does. So that made me want to learn more about LLVM. The code related to this post can be found here.
Overview of LLVM project
So what is LLVM. Here is a quote from the website.
The LLVM Project is a collection of modular and reusable compiler and toolchain technologies. Despite its name, LLVM has little to do with traditional virtual machines. The name “LLVM” itself is not an acronym; it is the full name of the project.
Source: https://llvm.org/
So my short description of the project based on what I have learned so far, is that previously most compilers reinvented the wheel for a lot of their functionality and a lot of project had very similar but different tooling. The idea of this project was to abstract out the various components of the tool chain. This would then allow writers of a new language or compiler to focus on their language and not have to focus on optimization and architecture specific logic.
Below is a nice diagram from “Intro to LLVM” by Chris Lattner from the documentation page in the LVM project.
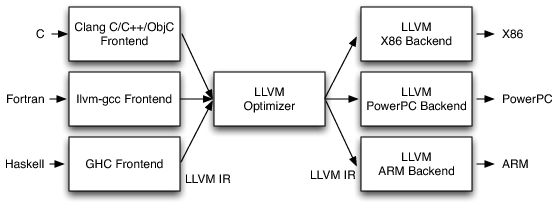
This is some of the motivations behind Java when it was created, but LLVM is not a VM in the same way the JVM. LLVM bytecode can be run using a JIT/Interpreter, but also can be built into a platform dependent executable. So LLVM code is not build once run anywhere.
So in writing a compiler for a new language, you can focus on parsing and translating your new language to LLVM IR, and then use existing tools in the LLVM tool chain to provide optimizations and target a backend.
Some of the key terms that I will be using here are the following:
LLVM IR – LLVM Intermediate Representation – Text/Human readable language that is some ways is similar to your typical architecture assembly language.
LLVM BC – LLVM Byte Code – Binary version of the above.
Commands That I Use Below
llvm-as – LLVM assembler
This program assembles .ll text files to .bc binary files.
It reads a file containing human-readable LLVM assembly language, translates it to LLVM bitcode, and writes the result into a file or to standard output.
Source: https://llvm.org/docs/CommandGuide/llvm-as.html
llvm-dis – LLVM disassembler
This program disassembles .bc binary files to .ll text files.
The llvm-dis command is the LLVM disassembler. It takes an LLVM bitcode file and converts it into human-readable LLVM assembly language.
Source: https://llvm.org/docs/CommandGuide/llvm-dis.html
llc – LLVM static compiler
The program compiles either .bc or .ll files into architecture assembly language .s text files.
The llc command compiles LLVM source inputs into assembly language for a specified architecture. The assembly language output can then be passed through a native assembler and linker to generate a native executable.
Source: https://llvm.org/docs/CommandGuide/llc.html
lli – directly execute programs from LLVM bitcode
Runs either .bc or .ll directly without statically compiling.
It takes a program in LLVM bitcode format and executes it using a just-in-time compiler or an interpreter.
Source: https://llvm.org/docs/CommandGuide/lli.html
Example with C
Source for test
I decided to start off with a very trivial example with C to see what I would be seeing. So I started with this program:
#include <stdio.h>
int main() {
printf("Hello World!\n");
return 0;
}Generate the IR code
When I compiled this to emit the LLVM representation.
clang -S -emit-llvm main.cThe result of that is this very concise blob of code, that makes sense because C has always being a small abstraction away from assembly.
; ModuleID = 'main.c'
source_filename = "main.c"
target datalayout = "e-m:o-i64:64-f80:128-n8:16:32:64-S128"
target triple = "x86_64-apple-macosx10.14.0"
@.str = private unnamed_addr constant [14 x i8] c"Hello World!\0A\00", align 1
; Function Attrs: noinline nounwind optnone ssp uwtable
define i32 @main() #0 {
%1 = alloca i32, align 4
store i32 0, i32* %1, align 4
%2 = call i32 (i8*, ...) @printf(i8* getelementptr inbounds ([14 x i8], [14 x i8]* @.str, i32 0, i32 0))
ret i32 0
}
declare i32 @printf(i8*, ...) #1
attributes #0 = { noinline nounwind optnone ssp uwtable "correctly-rounded-divide-sqrt-fp-math"="false" "disable-tail-calls"="false" "less-precise-fpmad"="false" "no-frame-pointer-elim"="true" "no-frame-pointer-elim-non-leaf" "no-infs-fp-math"="false" "no-jump-tables"="false" "no-nans-fp-math"="false" "no-signed-zeros-fp-math"="false" "no-trapping-math"="false" "stack-protector-buffer-size"="8" "target-cpu"="penryn" "target-features"="+cx16,+fxsr,+mmx,+sahf,+sse,+sse2,+sse3,+sse4.1,+ssse3,+x87" "unsafe-fp-math"="false" "use-soft-float"="false" }
attributes #1 = { "correctly-rounded-divide-sqrt-fp-math"="false" "disable-tail-calls"="false" "less-precise-fpmad"="false" "no-frame-pointer-elim"="true" "no-frame-pointer-elim-non-leaf" "no-infs-fp-math"="false" "no-nans-fp-math"="false" "no-signed-zeros-fp-math"="false" "no-trapping-math"="false" "stack-protector-buffer-size"="8" "target-cpu"="penryn" "target-features"="+cx16,+fxsr,+mmx,+sahf,+sse,+sse2,+sse3,+sse4.1,+ssse3,+x87" "unsafe-fp-math"="false" "use-soft-float"="false" }
!llvm.module.flags = !{!0, !1}
!llvm.ident = !{!2}
!0 = !{i32 1, !"wchar_size", i32 4}
!1 = !{i32 7, !"PIC Level", i32 2}
!2 = !{!"Apple LLVM version 10.0.0 (clang-1000.11.45.5)"}Run the code
I can then run this code directly using the following:
lli main.ll
Hello World!You can call transform the code to the binary byte code format by using the following:
llvm-as main.ll Generate Assembly Code
Then if you want to see the actual platform specific assembly code, then you can run the following, you can see the results from running this on my Mac here.
llc main.llExample with Rust
Since I have been learning Rust recently, I decided to have a similar test in Rust.
Source for test
$cargo new rust-llvm
Created binary (application) `rust-llvm` packagefn main() {
println!("Hello, world!");
}Generate the IR code
rustc --emit llvm-ir src/main.rsYou can see the IR code here.
Run the code
This is another link error, but I was unable to find a quick solution to pull in the dependencies from Rust, so I did not pursue if very far. I did find this and this that may lead somewhere, but I did not spend a huge amount of time on this.
lli main.ll
LLVM ERROR: Program used external function '__ZN3std2io5stdio6_print17hf28330b8a1759fecE' which could not be resolved!Generate Assembly Code
You can see the results from running this on my Mac here.
llc main.llExample with Swift
One of the other big projects that uses LLVM is Swift. Since I am writing this post on my Mac, I decide to do the same quick test with Swift.
Source for test
$swift package init --type executable
Creating executable package: swift-llvm
Creating Package.swift
Creating README.md
Creating .gitignore
Creating Sources/
Creating Sources/swift-llvm/main.swift
Creating Tests/
Creating Tests/LinuxMain.swift
Creating Tests/swift-llvmTests/
Creating Tests/swift-llvmTests/swift_llvmTests.swift
Creating Tests/swift-llvmTests/XCTestManifests.swiftprint("Hello, world!")Generate the IR code
swiftc -emit-ir main.swiftYou can see the IR code here.
Run the code
lli main.ll
LLVM ERROR: Program used external function '_swift_bridgeObjectRelease' which could not be resolved!I go an error. that is a link error missing and external dependency. After adding a couple of additional libraries, I can get the expected output.
lli \
-load=/Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/lib/swift/macosx/libswiftCore.dylib \
-load=/Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/lib/swift/macosx/libswiftSwiftOnoneSupport.dylib \
main.ll
Hello, world!Generate Assembly Code
You can see the results from running this on my Mac here.
llc main.llExample with C++
Just to round out this post, I decided to do a C++ example.
Source for test
#include <iostream>
int main() {
std::cout << "Hello world!" << std::endl;
return 0;
}Generate the IR code
clang++ -S -emit-llvm main.cppYou can see the IR code here. I was a bit surprised by how verbose this code is. It was by far the largest of the four tests.
Run the code
lli main.bc
Hello world!Generate Assembly Code
You can see the results from running this on my Mac here.
llc main.llFuture Areas to Research
One of the areas that I would like to spend some more time researching, is to try to understand what optimizations are already being done in the examples that I show above. The secondly, to learn how to take IR code generated by some language and send it through some optimization passes to see what happens. That may be a topic of a future post.

